如果说过去两年 AI 编程 Agent 的主战场在数字世界——写代码、修 bug、跑测试——那么 NVIDIA GEAR 实验室与 CMU、UC Berkeley 联合团队的最新工作,正在把这场「AI 训练 AI」的范式革命直接搬进物理世界。
北京时间 2026 年 6 月 18 日上线 arXiv 的论文 ENPIRE: Agentic Robot Policy Self-Improvement in the Real World,展示了一个名为 ENPIRE 的框架。它的核心主张简单而大胆:让前沿编程 Agent 自主完成真实机器人策略训练的完整闭环——从环境搭建、策略迭代、物理执行到日志分析与改进,人类研究员只需早上来读报告。
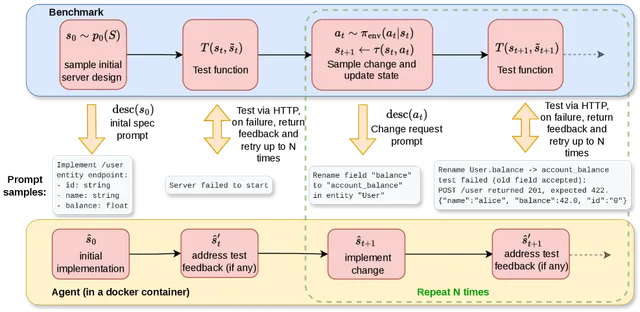
四个模块,一个闭环
ENPIRE 的名字本身就是其架构的缩写。它将物理世界中的机器人自研究拆解为四个模块:
Environment(EN,环境模块):编程 Agent 利用 SAM 3、cuRobo 等感知与规划工具 API,在人类仅提供少量成功/失败演示的前提下,自主构建自动重置与验证机制。任务完成后或失败时,机器人自动恢复初始状态;每次试验的结果由 Agent 设计的视觉-力觉混合奖励函数自动判定,无需人工打分。
Policy Improvement(PI,策略改进模块):Agent 审阅文献、提出假设,直接修改训练代码。它可以在多种范式间自由切换——启发式学习、行为克隆(BC)、离线/在线强化学习(RL)——并将改进后的策略提交到真实机器人上验证。
Rollout(R,执行模块):策略在单台或多台并行工作的 YAM 双臂机器人上执行,收集轨迹、视频与奖励信号,回传至 Agent 供下一步分析。
Evolution(E,进化模块):这也是 ENPIRE 最具野心的部分。在多机器人并行场景下,每台机器人配一个编程 Agent,各 Agent 在自己的 Git 分支上独立探索算法假设,然后自发地 cherry-pick、合并或放弃同行的成功方案——无需任何人类协调。
「我们 NVIDIA GEAR 实验室的一部分现在可以整夜自主迭代,」NVIDIA 高级研究经理、本文共同通讯作者 Linxi "Jim" Fan 在 LinkedIn 上写道,「我们早上来只需要读报告。」
99% 成功率,超越人类调参
ENPIRE 在四项高难度灵巧操作任务上进行了验证:
- Push-T:机器人通过非抓取式推挤,将 T 形块对齐到目标区域;
- Pin Insertion(插针):将针插入直径仅 4mm 的孔中,整理针盒;
- GPU Insertion(GPU 安装):将 GPU 芯片插入主板上的薄型插槽;
- Zip-tie Cutting(扎带剪切):抓取剪刀并剪断扎带尾部。
论文采用了更严苛的 pass@8 成功率指标——允许 8 次尝试,但每次尝试都能观察到前一次失败,因此同时衡量了精度与自主纠错能力。
结果令人瞩目:在 ENPIRE 框架下,前沿编程 Agent 在这些任务上达到了 99% 的成功率。在插针任务上,ENPIRE 甚至比同一团队此前的人机协同方法(human-in-the-loop)收敛得更快。
实验中使用了三款编程 Agent 进行横向对比:OpenAI Codex(GPT-5.5)、Anthropic Claude Code(Opus 4.7)和 Moonshot AI 的 Kimi Code(Kimi K2.6)。在模拟环境 Gym-PushT 中,Claude Code 和 Codex 均能在约 2 小时内达到 95% 成功率,而 Kimi Code 耗时约两倍。但在真实世界中,物理不确定性(接触摩擦、物体运动、硬件差异)构成了更大挑战:三款 Agent 中仅有两款在真实 Push-T 任务中成功。
机器人领域的 scaling law?
ENPIRE 最令人兴奋的发现之一,来自多机器人并行实验。团队分别测试了 1、4、8 个 Agent-机器人配对:
- 在 Push-T 任务中,8 个 Agent 将到达 1.0 归一化得分的时间从约 5 小时压缩到约 2 小时;
- 在插针任务中,8 个 Agent 将收敛时间从超过 1.5 小时缩短到约 40 分钟。
这意味着:增加物理机器人和编程 Agent 的数量,可以持续缩短达到目标性能所需的墙钟时间——一种类似大语言模型 scaling law 的规律,正在机器人领域浮现。
但 scaling 并非没有代价。团队提出了两个新指标来量化资源效率:平均机器人利用率(MRU)和平均 Token 利用率(MTU)。实验结果揭示了一个值得警惕的趋势:随着 Agent 数量增加,MRU 反而下降——Agent 花了更多时间阅读同行的分支日志、总结实验报告,而非实际操作机器人。Token 消耗也呈超线性增长:8 个 Agent 的 Token 总预算远超单 Agent 的 8 倍。
换句话说,更大的团队确实能更快到达终点,但单位效率在下降。这为未来的优化指出了明确方向:如何让 Agent 们更聪明地协作,而非简单地堆更多机器人。
从代码到物理世界:AI 自研究的范式跳跃
ENPIRE 的意义远不止于一个机器人训练框架。它标志着 AI 自研究(autoresearch)从数字世界向物理世界的关键跨越。
过去几年,AI Scientist、Agent Laboratory 等项目展示了 LLM 在数字环境中自主完成研究循环的能力——提出假设、运行实验、分析结果、撰写论文。但这些系统的实验始终停留在模拟器或代码执行层面。ENPIRE 首次将这一范式搬到了真实机器人硬件上:Agent 面对的不仅是代码错误,还有光照变化、接触摩擦、机械磨损等物理世界的不确定性。
论文在 Related Work 部分明确指出:「此前没有任何系统在显式硬件预算下自主运行和优化物理机器人研究循环——经典的机器人科学家系统使用固定装置且不自行编写工具,而 LLM 研究 Agent 从未接触过真实机器人。」
这种跨越之所以可能,关键在于 ENPIRE 将物理交互抽象为编程 Agent 可理解的 Gym API。一旦环境构建完成,Agent 面对的就是一个标准化的 reset() → step() → get_reward() 循环,与它在数字环境中熟悉的接口别无二致。
开源与未来
团队已宣布将 ENPIRE 开源。Jim Fan 表示,目标是让「任何人都能在家里搭建自己的自运行机器人实验室」。
论文也坦诚地列出了当前局限:机器人和 GPU 资源利用率不足、Token 成本随团队规模超线性增长、以及当前仅在相对结构化的操作任务上验证。但方向已经明确——编程 Agent 不再只是程序员的助手,它们正在成为物理世界中的自主研究者。
作者团队阵容堪称豪华:UC Berkeley 的 Ken Goldberg(机器人领域泰斗)、NVIDIA GEAR 的 Linxi "Jim" Fan 与 Yuke Zhu、CMU 的 Guanya Shi 共同指导,第一作者 Wenli Xiao 等来自 NVIDIA、CMU 和 UC Berkeley 三所机构。
在这个 AI 自研究从代码走向物理的转折点上,ENPIRE 的回答是:让机器人在夜里自己学会新技能,人类早上来读报告。