摘要
当前大语言模型(LLM)的开发范式存在一个根本性瓶颈:每次扩展模型能力,都需要人工设计静态数据集或奖励函数,手动启动一轮新的训练。Sakana AI 在 ICLR 2026 上发表的 AC/DC(Assessment Coevolving with Diverse Capabilities)框架试图打破这一限制——它让 LLM 种群与合成任务在同一个开放式循环中协同进化,模型通过合并产生新能力,任务通过合成数据不断翻新,整个过程无需人工介入。
现有范式的瓶颈:每一次训练都需要「手动点火」
今天的前沿模型开发遵循一条清晰的流水线:预训练 → 后训练(SFT + RLHF)→ 评估。每当研究者希望模型获得新能力——更强的数学推理、更精准的代码生成、更丰富的创意写作——就必须重新设计数据集、调整奖励函数,并启动一轮新的训练。这个过程不仅昂贵,还有一个更隐蔽的问题:它天然倾向于产生「一个模型解决所有问题」的单体架构。
这种思路的困境正在逐渐显现。Kumar 等人(2025)提出的「断裂纠缠表示假说」指出,单一模型在试图同时掌握大量异质能力时,内部表征会出现冲突;而 Li 等人(2025)的研究则揭示了大模型推理的惊人环境成本。更根本的是,正如 Stanley 和 Lehman 在《Why Greatness Cannot Be Planned》中论证的:追求单一最优解的优化过程,往往会错过真正具有突破性的中间发现。
AC/DC 的出发点正是对这一范式的反思:如果人类文明的集体智能不是靠一个超级大脑运转,而是靠无数专精个体的协作,为什么 LLM 的发展一定要走单体路线?
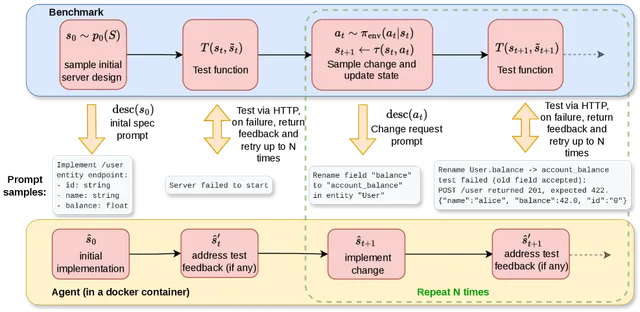
AC/DC 如何工作:两个归档的协同进化
AC/DC 的核心设计是一个双归档协同进化系统。它同时维护两个「档案库」:
模型归档(Model Archive):存储通过进化搜索发现的高质量、多样化 LLM。AC/DC 从至少三个种子模型(同一基础架构的不同微调版本)出发,通过交叉(crossover)和变异(mutation)操作生成后代,再用 Dominated Novelty Search(DNS)算法筛选出在能力空间中互补的个体。
任务归档(Task Archive):存储由「科学家 LLM」(一个较大的模型,如 Qwen2.5-72B-Instruct)生成的合成任务。每个任务包含问题-答案对和 Python 评分函数。任务通过难度自适应、新颖性过滤、反思验证三道关卡后进入归档,持续为模型进化提供不断升级的挑战。
两个归档在每个代际中相互驱动:模型在任务上接受评估,生成技能向量(skill vector);任务根据模型群体的通过率调整难度方向;更复杂的任务催生更有能力的模型,更有能力的模型又反过来要求更具挑战性的任务。这种「军备竞赛」式的动态,正是开放式进化(open-endedness)的引擎。
模型合并:交叉与变异
AC/DC 的模型进化建立在演化模型合并(EvoMerge,Akiba et al. 2025)的基础上,但引入了专门针对 LLM 的操作:
交叉(Crossover):随机采样两个父模型,使用任务向量(task vector)的加权线性插值进行合并。任务向量定义为父模型参数与基础模型参数之差:τ = θ_parent − θ_base。这一设计借鉴了 CycleQD(Kuroki et al. 2025)的做法,让合并后的模型继承两个父模型各自擅长的能力方向。
变异(Mutation):对合并后模型权重矩阵的奇异值施加噪声扰动。具体而言,对每个权重矩阵 W 进行 SVD 分解 W = UΣV^T,然后扰动 Σ 中前 k 个奇异值再重构。这一操作在保留权重矩阵整体几何结构的同时,引入表征层面的变化,为能力空间探索提供了额外的多样性。
每代生成的后代在合成任务上被评估,其表现被编码为二进制的技能向量——每个维度对应一个任务是否被正确解决。随后,DNS 算法根据技能向量计算局部竞争适应度(local competition fitness),优先保留那些与更优解在行为空间中距离较远的个体,从而维护种群的多样性。
合成数据:任务如何自我进化
任务的生成同样是一场进化。科学家 LLM 从任务归档中采样一个父任务和三个随机参考任务,根据父任务的难度分布(由当前模型种群的平均通过率决定)确定适应方向——增加难度、降低难度,或生成全新变体。
生成的任务需经过三道筛选:
- 新颖性过滤:使用嵌入向量在全局归档中进行余弦相似度检索,由评判 LLM 判断新任务是否与已有任务足够不同。
- 反思与验证:科学家 LLM 先尝试自己解答生成的任务,执行评分函数,识别编译错误或逻辑问题并进行迭代修正。
- 最低标准过滤:移除所有模型都无法解答的「不可能任务」,替换为其父任务。
在一项由三位专家评审的人类研究中,AC/DC 生成的合成任务达到了 97.8% 的正确率,68.9% 被判定为与标准 benchmark 分布外(OOD),37.8% 被评为具有创造性。作为对比,标准 benchmark 任务的 OOD 率仅为 10.2%,创造性评分仅 6.1%。
评估:Coverage 指标
AC/DC 使用 Coverage 而非传统准确率来衡量模型群体的能力。Coverage 定义为「至少有一个模型正确回答」的问题占总问题的比例。这一指标捕捉的是集体智能的互补性——一个模型不会的,另一个模型可能会。
论文还引入了 Best-of-N(BoN)评估,即在标准 benchmark 上从多个候选答案中选出最佳答案,测试 Coverage 的提升能否转化为实际部署场景中的收益。
与现有模型合并技术的区别
模型合并并非新概念。从 Model Soups(Wortsman et al. 2022)的简单权重平均,到 Task Arithmetic(Ilharco et al. 2023)的任务向量加减,再到 TIES(Yadav et al. 2024)和 DARE(Yu et al. 2024)通过剪枝和符号一致性来减少合并冲突,这个领域在过去两年中发展迅速。
AC/DC 与这些方法的关键区别不在于合并算法本身,而在于合并的目的和运作方式:
- Model Soups / TIES / DARE 是「一次性」工具:人类选择要合并的模型和合并系数,产生一个最终模型,过程结束。
- EvoMerge(Sakana AI 的前序工作)将合并自动化,但仍然是目标驱动的:用户指定期望的能力,进化算法搜索最优合并配方。
- AC/DC 则将合并嵌入一个持续运行的开放式系统中。没有预设的「目标能力」,没有终点。模型合并是手段而非目的——它的真正任务是不断产生新的能力组合,供自然选择(DNS)筛选。
正如论文作者在 X 上所说:「AC/DC 选择模型不是因为它们平均得分高,而是因为它们解决了种群中其他模型无法解决的问题。」
关键结果:小模型集体超越大模型
AC/DC 在 Qwen2、Qwen2.5、Qwen3 和 DeepSeek V1 四个模型家族上进行了实验,每种都从 7B(或 14B)参数的基础模型出发。主要发现包括:
Coverage 提升:在 N=8 配置下,AC/DC 种群相对于同家族 72B 大模型的 Coverage 平均提升 10.19%。以 Qwen2.5 为例,N=3 配置下使用仅 29% 的参数即超越 72B 模型 3.85%,N=8 配置下提升至 9.78%。
超越 GPT-4o:Qwen2.5 的 3 模型任务小组在 Coverage 上超越了 GPT-4o,且总参数量远低于后者。论文指出,这暗示着一个由小型、多样化、能力互补的模型组成的集体,可能拥有与单一前沿模型相当的知识覆盖。
持续进化:随着进化代数的增加,模型种群的 Coverage 和 MMLU/MMLU Pro 平均准确率持续提升,表明系统具有开放式改进的趋势。
消融实验:DNS 质量-多样性选择和 gibberish 过滤器(用于剔除退化模型的最低标准过滤)是最关键的组件,单独移除它们分别导致 Coverage 下降 2.39% 和 2.46%(N=3)。
对比先前的 QD 方法:AC/DC 在 N=8 时的 Coverage(69.00%)显著优于直接在 benchmark 数据集上优化的 DNS(66.48%)和 CycleQD(65.42%),而 AC/DC 自身从未见过任何 benchmark 数据。
一种新的 LLM 开发哲学
AC/DC 所代表的,远不止是一种新的训练技巧。它指向一种根本不同的 LLM 开发哲学——从「精心设计单次训练」转向「让模型种群在开放式环境中持续进化」。
这一转变有三个层面的含义:
第一,从模型到种群。 当前范式下,每次训练的目标是产出一个「更好的模型」。AC/DC 的目标是产出一个「更好的模型集体」——一群能力互补、风格各异的专家,它们组合起来能覆盖比任何单一模型更广的能力空间。
第二,从静态数据到动态环境。 传统训练依赖静态数据集,数据一旦确定就不再变化。AC/DC 中的任务归档是一个动态实体,它随模型能力的提升而不断升级,形成真正的「进化军备竞赛」。
第三,从目标驱动到开放式探索。 大多数 ML 系统的目标是预设的——最大化某个 benchmark 分数。AC/DC 不针对任何 benchmark 优化,它只是让进化的力量在质量-多样性空间中自由探索。正如 Lehman 和 Stanley(2011)在《Abandoning Objectives》中倡导的:有时候,放弃目标比追求目标更能带来突破。
Sakana AI 团队将 AC/DC 定位为「离 LLM 开发新范式更近一步」——在这个新范式中,现有模型不再是终点,而是通往更强大模型的「垫脚石」。这让人联想到 Clune(2020)提出的 AI-GA(AI-Generating Algorithms)愿景:让算法自己产生更好的算法,而非由人类工程师一步步设计。
局限与展望
AC/DC 也面临若干现实约束。合并效果依赖于种子模型的选择——微调过强、参数空间发散过大的模型合并效果不佳(论文在 Llama3 上的实验效果有限)。框架依赖一个固定的科学家 LLM 来生成任务,这限制了探索的上限。此外,AC/DC 主要通过交叉组合现有能力,而非让模型获得全新知识——这受限于种子模型的初始能力边界。
论文提出了几个值得关注的方向:用进化出的模型种群替代固定的科学家 LLM,实现递归自我改进;延长进化周期,研究长期开放式动态是否可持续;以及改进 BoN 选择方法,缩小集体模型与单体大模型在实际部署场景中的差距。
无论如何,AC/DC 已经证明了一件事:在 LLM 的世界里,整体可以大于部分之和——而且这个整体,不需要人类手动组装。