2026 年 6 月 3 日,英国竞争与市场管理局(CMA)依据《数字市场、竞争与消费者法》(DMCCA 2024)对 Google 搜索服务正式实施「行为要求」(Conduct Requirement),强制 Google 为内容出版商提供独立的 AI 功能退出机制。这是全球范围内,监管机构首次以法律强制力要求一家搜索平台将 AI 搜索与传统搜索的参与权「解绑」——出版商可以单独拒绝其内容被用于 AI Overviews、AI Mode 以及 AI 模型训练,而不必退出 Google 搜索整体。
这项裁决不仅改变了英国出版商与 Google 之间的权力等式,也为 AI 时代「内容–平台」关系的重构提供了第一个可被复制的监管范本。
裁决核心:让退出 AI 不再意味着退出搜索
此次裁决最关键的制度创新,在于打破了 Google 此前对「退出」的捆绑式设计。
在 CMA 介入之前,出版商若不想让自己的内容出现在 AI Overviews 中,唯一可行的技术手段是使用 NOSNIPPET 标签——但这会同时移除传统搜索结果中的摘要文本。CMA 在调查中援引了 Google 自己的一项研究(在 AI 产品出现之前完成):搜索结果中减少描述性文本导致出版商流量下降 45%。另一种选择是使用 Google-Extended 爬虫控制,但该工具只能阻止 Gemini 和 Vertex 等外部 AI 服务抓取内容,并不能阻止内容被用于 AI Overviews 或 AI Mode 的「grounding」。
换句话说,此前的退出选项是一个「全有或全无」的开关:要么参与 AI 搜索,要么承受整个搜索可见度受损的风险。对于英国这样一个 Google 占据超过 90% 搜索流量份额的市场,这种选项对于依赖搜索流量的出版商来说并不真实存在。
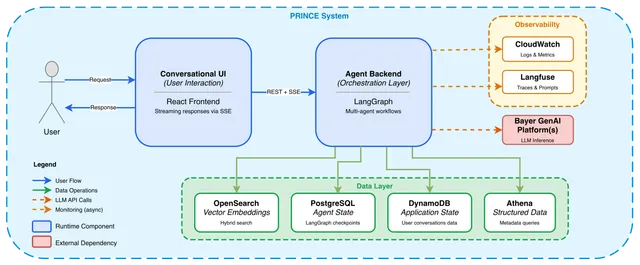
CMA 的新规要求 Google 在 Search Console 中提供一个独立的 toggle 开关,让网站所有者可以单独选择不参与生成式 AI 搜索功能(AI Overviews、AI Mode、AI Overviews in Discover),同时明确规定:这一选择不得被用作传统搜索结果的排名信号,已退出的出版商在传统搜索结果中的展示方式也不得有任何不同。Google 还不得通过第三方抓取工具等方式规避出版商的选择。
裁决范围:从 AI 搜索到模型训练的全链条覆盖
裁决的另一个重要特征是其范围之广。CMA 的要求不仅覆盖了 Google 搜索页面内的生成式 AI 功能,还延伸到了:
- AI 模型训练与微调:出版商可以拒绝其内容被用于训练和微调 Google 的 AI 模型。这是 CMA 在咨询期收到反馈后特意补充的条款,确保出版商对 AI 使用其内容的全部场景拥有控制权。
- Google 搜索之外的生成式 AI 服务:包括 Gemini 聊天机器人和 Vertex AI 开发平台对出版商内容的 training 和 grounding。
- 内容归属:Google 被要求确保 AI 生成结果中的出版商内容得到清晰、准确的 attribution,包括明确的链接。CMA 还要求 Google 发布关于其如何识别应归属内容、如何监控归属准确性的说明。
CMA 首席执行官 Sarah Cardell 在声明中表示:「随着 AI Overviews 等功能迅速重塑在线搜索,内容出版商——包括新闻机构——必须拥有适当的议价能力来控制其内容的使用方式。」她同时强调,CMA 将继续利用英国数字市场制度的「独特灵活性」来监控和应对未来的问题,并将在未来几周内宣布针对 Google 搜索业务的进一步行动。
背景:90% 市场支配力下的出版商困境
CMA 的干预并非凭空而来。2025 年 10 月,CMA 依据 DMCCA 首次将 Google 的通用搜索服务指定为具有「战略市场地位」(Strategic Market Status, SMS),为后续的监管干预奠定了法律基础。2026 年 1 月,CMA 提出了针对 Google 的初步行为要求方案,并进行了公开咨询。
推动监管加速的,是出版商群体持续恶化的生存数据。自 Google 在搜索结果页面顶部大规模部署 AI Overviews 以来,出版商的搜索引荐流量经历了显著下滑:
- Google 自家的数据显示,AI Overviews 月活用户已超过 25 亿,AI Mode 月活用户超过 10 亿。
- 第三方研究机构 Define Media Group 对 64 个网站的分析显示,自 Google 扩展 AI Overviews 以来,有机搜索点击量下降了 42%。
- 皮尤研究中心 2025 年 7 月的一项研究发现,当 AI Overviews 出现在搜索结果顶部时,仅 1% 的用户会点击其引用的链接。
- 新闻媒体联盟(News/Media Alliance)主席兼 CEO Danielle Coffey 在声明中直言:「出版商被 Google 将传统搜索和 AI 搜索爬虫捆绑在一起的决定扣为人质太久了。」
CMA 在调查中认定,出版商「目前没有足够的选择权」来决定其内容在 Google AI 生成回复中的使用方式,而且由于 Google 的市场支配地位,出版商「没有现实的选择,只能允许其内容被抓取」。CMA 的结论是:Google 通过限制出版商对内容后续使用的控制,在获取 AI 回复所需内容的同时,限制了出版商变现其内容的能力——这种能力是 Google 的竞争对手无法匹敌的。
CMA 的逻辑:退出权创造了「进入」的议价空间
CMA 监管逻辑中最精妙的一层,在于其对「opt-out」和「opt-in」之间关系的理解。
裁决的核心理念是:赋予出版商真正可执行的退出权,本身就是一种谈判筹码的再分配。在裁定公告中,CMA 明确指出,退出机制将「使出版商——如新闻机构——在与 Google 就 AI 功能中使用其内容进行谈判时处于更强的位置」。换句话说,opt-out 的存在本身创造了 opt-in 的议价空间——只有当出版商可以说「不」时,Google 才需要认真谈判说「是」的条件。
这一逻辑得到了英国新闻媒体协会(NMA)首席执行官 Owen Meredith 的认可,他称裁决「强烈欢迎」,但同时也指出仅靠行为性补救措施可能不够,并敦促 CMA 考虑「搜索爬虫和 AI 产品爬虫的完全物理分离」。Meredith 进一步呼吁政府支持 CMA 采取更快的行动,包括「要求 Google 与出版商就公平合理的支付条款进行谈判」。
但并非所有出版商都如此乐观。Raptive 首席战略官 Paul Bannister 将退出选项称为「荒谬的」,并质疑是否有出版商会真正使用它:「给出版商一个控制 AI Overviews 或 AI Mode 的前端开关,不是真正的控制;这是 Google 在发电厂还在运转的时候,递给出版商一个电灯开关。」
Google 的回应:从英国试点到全球推广
Google 对 CMA 裁决的公开回应显得配合而克制。在裁决公布的同一天,Google 搜索生态系统总经理 Mrinalini Loew 发表博客,宣布正在 Search Console 中测试新的控制功能,让网站所有者可以「管理其链接和内容在生成式 AI 搜索功能中的显示方式」。
Google 承诺:该控制不会被用作传统搜索排名信号;该功能将在英国子集出版商中先行测试,随后「全球推广」。Google 还同时宣布了新的 Search Console 洞察功能,包括展示次数指标以及哪些页面出现在 AI 回复中、出现在哪些国家。
但 Google 也试图在叙事上保持主动权。博客中强调 AI Overviews 拥有超过 25 亿月活用户,AI Mode 超过 10 亿,声称人们「对搜索更加满意,搜索频率更高」。Google 还列举了近期增加的 inline links、网站预览和 Preferred Sources 等功能,以展示其已经在改善出版商体验。
从时间线来看,Google 有九个月的时间来完成所有变更的实施,但 CMA 期望关键控制功能在此期限之前就能向出版商开放。Google 还需每六个月提交并发布合规报告,包含关键数据和指标。
出版商的两难:一个名义上存在、实际上难以使用的权利
尽管裁决在纸面上是出版商的一次胜利,但深入分析后,其实际效用面临多重质疑。
首先是默认状态问题。 该机制是 opt-out 而非 opt-in——出版商默认被纳入 AI 功能,需要主动操作才能退出。前 Bauer Media Group 全球受众发展总监 Stuart Forrest 指出:「如果这是 opt-in,Google 就必须向我们证明为什么应该让我们使用他们的内容。相反,他们默认保留我们在其中,却不给我们判断 AI 搜索是否真的在伤害我们业务所需的点击数据。」
其次是数据缺失。 Google 虽然在 Search Console 中提供了 AI 功能的展示次数(impressions)数据,但并未提供 AI 功能的点击量(clicks)数据。这意味着出版商无法判断 AI Overviews 到底是在为其带来流量,还是只是在搜索结果页面上回答问题、扼杀点击。路透社数字业务总经理 Phil Andraos 表示:「数据不够。如果有,我们可以很快做出决定。现在只能更谨慎地评估,可能还需要测试。」
第三是捆绑风险。 Candr Media Group CEO Chris Dicker 警告,退出选项将 AI Mode 和 AI Overviews 等多个服务捆绑在一起,而非让出版商逐个控制。他担心 Google 未来可能将 Discover 也纳入同一框架,而许多出版商如今依赖 Discover 作为主要流量来源,「因此无法现实地选择退出」。
第四是竞争性陷阱。 如果大多数出版商出于恐惧而选择不退出——这正是许多行业观察者预判的结果——Google 可以将低退出率当作「出版商对 AI 搜索满意」的证据,进一步削弱更严格监管的合理性。Forrest 担心,英国协议可能成为其他监管机构复制的模板,一个建立在 opt-out 和不完整数据基础上的较弱标准可能被「出口」到布鲁塞尔。
Digital Content Next CEO Jason Kint 则从另一个角度指出,裁决仅涉及出版商内容在 AI 搜索中的未来使用,并未触及「已被强行获取并用于训练 AI 模型的大量受保护内容」。他同时提到美国联邦法院已裁定 Google 在搜索领域拥有非法垄断地位,因此「结束因缺乏真正的退出训练选择而对开放网络造成的伤害的禁令救济,正在议程上」。
全球涟漪:从伦敦到布鲁塞尔,再到华盛顿
CMA 裁决的全球影响已在显现。Google 主动宣布将退出机制「全球推广」,这本身就意味着英国监管的外溢效应——一旦工具建成,其他市场的出版商也将获得同样的技术能力。
在欧盟层面,欧洲委员会已于 2026 年 1 月启动了针对 Google 的 DMA 规范程序,要求 Google 向第三方 AI 服务提供商提供「同等有效的访问权限」。欧盟还对 Google 在搜索结果中的自我优待行为展开了初步调查。CMA 的裁决为欧盟提供了一个可供参考的「最小可行干预」模板——但也可能被用作论据,证明更温和的行为性补救已足够,从而推迟更结构性的拆分措施。
在美国,News/Media Alliance 已呼吁 FTC 和 DOJ 调查 Google 对数字新闻出版的「垄断性侵占」,Penske Media 诉 Google 案则正在推进。英国裁决可能为美国法院和监管机构提供一个可观察的「自然实验」:看看 opt-out 机制在实际中如何运作,以及它是否真的能改变 Google 与出版商之间的价值分配。
值得注意的是,CMA 明确表示,此次行为要求「不会解决出版商目前面临的所有问题」,但将其定位为「解决更广泛问题的重要前提条件」——即出版商能否就 Google 使用其内容谈判合理条款。CMA 还警告,如果 Google 实施不力,将「推进进一步措施以确保 Google 与出版商之间的公平价值交换」。
在 AI 重塑信息获取方式的时代,英国 CMA 的裁决标志着一个关键时刻:监管者首次以法律手段在 AI 搜索和传统搜索之间划出了一条边界,并试图将选择权交还给内容的创造者。但这条边界到底是一道真正的防火墙,还是 Google 合规策略中的一道虚线,取决于未来几个月中的具体实施——以及出版商是否敢于按下那个开关。